
type
status
date
slug
summary
tags
category
icon
password
深度学习前置知识
深度学习快速上手,首先你需要了解到一些前置知识,也就是机器学习,你需要了解他的算法,聚类算法,回归算法,等等,深度学习是一个漫长的过程,希望读者坚持不懈,为科研事业创造出自己的价值,这也是我们学习的意义,至此.我们可以真正开始了
深度学习为什么叫做深度学习,难道我们之前学习的都是浅度学习吗?,首先我们介绍一下深度学习是个什么东西.
深度学习是机器学习的一个分支,深度学习采用多层 神经网络(称为深度神经网络)来模拟人脑的复杂决策能力。某种形式的深度学习可为我们当今生活中的大部分人工智能 (AI)应用程序提供动力。
简而言之,你可以把他当作科学界的一大反向和领域,机器学习是一个大类.他包含在AI中,深度学习其实就是利用神经网络的模型通过训练数据,来达到人脑的决策能力,我们可以通过某些算法给同一个数据的集合相同特征传入神经网络模型,然后让他智能决策聚类
深度学习的工作原理
深度学习神经网络或人工神经网络尝试结合数据输入,权重和偏差来模仿人脑.这些元素协同工作,以准确识别,分类和描述数据中的对象
深度神经网络由多层互连节点组成,每个节目点都建立在前一层的基础上,以细化和优化预测或分类.这种通过网络进行的计算是前向传播.深度神经网络的输入层和输出层称为可视层,深度学习模型在输入层提取数据进行处理,在输出层进行最终预测或分类
另一个称作反向传播的过程使用梯度下降等算法计算预测中的误差然后再各层反向传播函数的权重和偏差来进行调整,以此训练模型.正向传播和反向传播龚祖同支持神经光网络进行预测并相应的纠正错误.算法会逐渐变得更加准确
这些是用最简单的术语来描述最简单的深度神经网络类型,然而深度学习算法非常复杂,并且是不同类型的神经网络可以解决特定的问题或处理特定的数据集.例如
卷积神经网络(CNN)主要用于计算机视觉和图像分类应用,可以检测图像内的特征和模型,帮助完成目标检测或识别等任务,2015年,一个CNN首次在物体识别挑战中击败了人类
循环神经网络(RNN)利用顺序或时间序列数据,通常用于自然语言和语音识别应用程序中
机器学习基本范式
我们首先来回顾下机器学习中两种基本的学习范式,如图所示,一种是监督学习,一种是无监督学习(林轩田课程中把机器学习范式分为监督学习、半监督学习、无监督学习以及强化学习)。
监督学习利用大量的标注数据来训练模型,模型的预测和数据的真实标签产生损失后进行反向传播(计算梯度、更新参数),通过不断的学习,最终可以获得识别新样本的能力。
无监督学习不依赖任何标签值,通过对数据内在特征的挖掘,找到样本间的关系,比如聚类相关的任务。
有监督和无监督最主要的区别在于模型在训练时是否需要人工标注的标签信息。
无监督学习中被广泛采用的方式是自动编码器(autoencoder):
理解下面这张图

信息通过树突进入,细胞核接收到通过轴突进行传送信号,然后经过某些激活,最后刺激产生一个输出
这是一个简单的感知机


所谓就是一个加权求和的过程
下面就是一个多层的一个感知机,他的特点就是有多个神经元层,以及相邻的两个层的神经元彼此都有连接,因此也叫深度神经网络


前向传播和反向传播
………
Softmax/turn

Attention
Attention 的本质思想
从人类的视觉注意力可以看出,注意力模型 Attention 的本质思想为:从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略不重要的信息。
在详细讲解 Attention之前,我们在讲讲 Attention的其他作用。之前我们讲解 LSTM 的时候说到,虽然 LSTM 解决了序列长距离依赖问题,但是单词超过 200 的时候就会失效。而 Attention 机制可以更加好的解决序列长距离依赖问题,并且具有并行计算能力。现在不明白这点不重要,随着我们对 Attention 的慢慢深入,相信你会明白。
首先我们得明确一个点,注意力模型从大量信息 Values 中筛选出少量重要信息,这些重要信息一定是相对于另外一个信息 Query 而言是重要的,例如对于上面那张婴儿图,Query 就是观察者。也就是说,我们要搭建一个注意力模型,我们必须得要有一个 Query 和一个 Values,然后通过 Query 这个信息从 Values 中筛选出重要信息。
通过 Query 这个信息从 Values 中筛选出重要信息,简单点说,就是计算 Query 和 Values 中每个信息的相关程度。
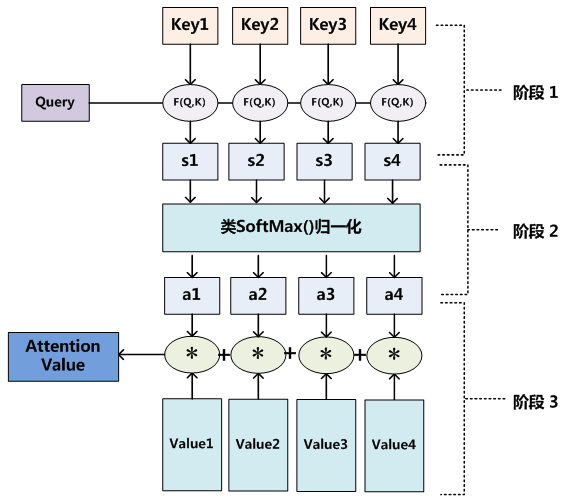
再具体点,通过上图,Attention 通常可以进行如下描述,表示为将 Query(Q) 和 key-value pairs(把 Values 拆分成了键值对的形式) 映射到输出上,其中 query、每个 key、每个 value 都是向量,输出是 V 中所有 values 的加权,其中权重是由 Query 和每个 key 计算出来的,计算方法分为三步:

为什么这里的softmax要除以,因为softmax是一个指数级的式,随着两者差距越来越小就分的效果越好,这样就会出现一个问题
当:

就会比较离谱,所以要除以一个key的维度开根号,dk=dim of key
Loss(笔记)
一.交叉熵损失 Cross entropyLoss
当训练有 C 个类别的分类问题时很有效. 可选参数 weight 必须是一个1维 Tensor, 权重将被分配给各个类别. 对于不平衡的训练集非常有效。
公式:
在多分类任务中,经常采用 softmax 激活函数+交叉熵损失函数,因为交叉熵描述了两个概率分布的差异,然而神经网络输出的是向量,并不是概率分布的形式。所以需要 softmax激活函数将一个向量进行“归一化”成概率分布的形式,再采用交叉熵损失函数计算 loss
交叉熵损失(CrossEntropyLoss)是深度学习中常用的一种损失函数,尤其适用于分类问题。它衡量模型的预测概率分布与真实标签之间的差异。
交叉熵损失的计算方式依赖于模型的输出形式。通常,在分类问题中,模型会输出一个概率分布,表示每个类别的预测概率。而真实标签通常以one-hot编码的形式表示。
交叉熵损失的计算方式如下:
CrossEntropyLoss = -∑(y * log(ŷ))
其中,y表示真实标签的概率分布(one-hot编码),ŷ表示模型的预测概率分布,∑表示求和运算。
交叉熵损失首先将真实标签的概率分布与模型的预测概率分布进行逐元素相乘,然后取对数,最后对所有元素求和并取相反数。通过取相反数,损失值越小表示模型的预测越准确。
交叉熵损失的优点是能够有效地激励模型输出的概率分布接近真实标签的分布。它在训练过程中可以推动模型更快地收敛,并在分类任务中产生更好的结果。
在训练过程中,通过最小化交叉熵损失来调整模型的参数,使模型能够更好地拟合训练数据,并提高分类准确性。
二、均方误差损失 MSELoss
均方误差损失(Mean Squared Error Loss),通常简称为MSE损失,是深度学习中常用的一种损失函数,用于衡量模型预测值与真实值之间的差异。
MSE损失计算方式如下:
MSE损失 = 1/n * ∑(y - ŷ)^2
其中,y表示真实值,ŷ表示模型的预测值,n表示样本数量,∑表示求和运算。
MSE损失首先计算预测值与真实值之间的差异,然后将差值平方,再对所有样本进行求和,最后除以样本数量,得到平均值。因此,MSE损失是预测值与真实值差异的平方的平均值。
MSE损失的优点是对较大的预测误差有较高的惩罚,因为差异的平方放大了较大的误差。同时,MSE损失在数学性质上也比较好,易于计算和求导。
在训练过程中,通过最小化MSE损失来调整模型的参数,使模型能够更好地拟合训练数据,并尽可能减少预测值与真实值之间的差异。
三、多标签分类损失 MultiLabelMarginLoss
MultiLabelMarginLoss(多标签边际损失)是一种用于多标签分类任务的损失函数。它适用于同时处理多个标签,并鼓励模型在每个标签上的预测与真实标签之间有较大的差异。
MultiLabelMarginLoss的计算方式如下:
MultiLabelMarginLoss = max(0, margin - y * ŷ_i + (1 - y) * ŷ_j)
其中,y是一个二进制矩阵,表示真实标签,每行对应一个样本的标签,ŷ是一个浮点数矩阵,表示模型的预测输出,每行对应一个样本的预测概率,margin是边际参数。
MultiLabelMarginLoss对于每个样本和每个标签都计算了一个边际损失。对于每个样本,该损失函数选择预测得分与真实标签之间的差异最大的两个标签,并计算它们之间的边际损失。如果两个标签之间的差异小于边际,则损失为0,表示模型已经达到了边际的要求。如果差异大于边际,则损失为差异的负值,以惩罚模型对标签的错误排序。
MultiLabelMarginLoss的优点是能够处理多标签分类任务,并对模型在每个标签上的预测进行差异化的训练。它帮助模型在每个标签上进行更准确的分类,从而提高多标签分类任务的性能。
通过最小化MultiLabelMarginLoss来调整模型的参数,可以使模型更好地分类多个标签,并提高多标签分类任务的准确性。合理选择边际参数可以平衡模型对标签差异的要求。
torch.nn.MultiLabelMarginLoss(reduction='mean')
对于mini-batch(小批量) 中的每个样本按如下公式计算损失:
Normalization
一些笔记……Layer Normalization
batch是对不同特征(向量)的相同维度做标准化
layer是对相同特征(向量)的不同维度做标准化(行列)
Normalization和activation区别就是一个是做到0,1的范围(相当于数学的分布,一个是直接将原来的输入归一到[0,1]区间
看到有一句形容softmax非常合适:
“max” because amplifies probability of largest
“soft” because still assigns some probability to smaller
Transformer结构

他的add&Norm就是用的residual block(残差块)+layer Normalization进行搞的
residual block我理解是将输出的output加上原始的input…
残差块引入了跳远连接(skip connection),确保信号可以直接传递,避免梯度消失问题。通过这种方式,不仅没有负面影响,反而增强了网络的表现。当需要调整尺寸时,可通过系数矩阵来保持维度一致性。
encoder里面就相当于提取特征
Decoder里面的结构,有一个begin和end,可以相同,也可以不同,用于结束,masked就是屏蔽掉后面的输入,其实也就是只跟前面输入的作相关
系统不知道输出的长度是多少,不过我们也希望机器可以去学习,也可以直接输出一个长度
nat:非自回归
at:自回归
AT:

以上是AT,还有NAT
NAT:

如何去决定natdecoder的长度?
1.输出另一个预测器的长度
2.输出一个长序列,忽略end符号
优点:并行,可以控制输出长度,而且比at要快,不是和at一样,一个一个的输入输出,而是每次都根据begin去输出
但是往往不如at的效果好;;multi-modality如下有讲解
![[DLHLP 2020] Non-Autoregressive Sequence Generation (由助教莊永松同學講授)](https://www.notion.so/image/https%3A%2F%2Fwww.youtube.com%2Fs%2Fdesktop%2Fdd166493%2Fimg%2Flogos%2Ffavicon_144x144.png?table=block&id=129d1a9a-b011-8099-974f-cda9ba9b3da5&t=129d1a9a-b011-8099-974f-cda9ba9b3da5)
![[DLHLP 2020] Non-Autoregressive Sequence Generation (由助教莊永松同學講授)](https://www.notion.so/image/https%3A%2F%2Fi.ytimg.com%2Fvi%2FjvyKmU4OM3c%2Fmaxresdefault.jpg?table=block&id=129d1a9a-b011-8099-974f-cda9ba9b3da5&t=129d1a9a-b011-8099-974f-cda9ba9b3da5)
Self—Supervised learning
什么是 Self-Supervised Learning
首先介绍一下到底什么是 SSL,我们知道一般机器学习分为监督学习,非监督学习和强化学习。而 self-supervised learning 是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务。其主要的方式就是通过自己监督自己
比如把一段话里面的几个单词去掉,用他的上下文去预测缺失的单词,或者将图片的一些部分去掉,依赖其周围的信息去预测缺失的 patch。
Auto Encoder
什么是Auto Encoder?这里引用了一下李宏毅老师ppt来说,就是想让输入的这个图像,和他经过encoder,decoder后输出的图像尽可能的相似,为什么不直接输出?因为我们的目的是让机器学习feature……类似于降维

这也是无监督学习,跟SSL(self-supervised learning)的pretrain相同,都是不需要标签可以完成的东西,这上面也叫做重建(这个过程),重建的过程就是网络学习图片特征的过程.这就是autoencoder常见用于下游任务的做法(Downstream)
那么不一定图片都是3x3才能表示,你会发现一个向量有限的变化,然后就可以用一个2维的矩阵来表示他,可以理解为特征压缩,而encoder就是做这件事情,化繁为简,把3x3用2维来表示,还能用更少的训练数据去训练出原来的效果,把复杂的向量用更简单的方式去表示
De-noising Auto-encoder
降噪自动编码
就是把原来需要输入的图片,加入一些噪点加入一些无关的资讯,再进行autoencoder,让他还原出加入噪点之前的图像,他多了一个任务就是降噪,就是De-noising,其实现在的bert也有他的影子,我们加入masking,其实就是masking就相当于这个denoising,bert模型就是encoder,输出就是embedding,最后linear(不一定是linear)的模型就是decoder,最后还原出来

Featuren Disentangle(我的理解是特征解耦合

当我们autoencoder的时候,机器学习到了其中的特征,但是这个特征是在一个大的向量中,我们不知道在哪个维度中,而disentangle就是让这些一切都变得清晰,解耦,就是把一堆东西给他分离出去.
那么我们就可以做这样的事情:把说话人A的声音和文字提取出来,让说话人B用说话人B的声音去说说话人A的语言

application:柯南的领结变声器(hahaha,,并不是这个名字,他的名字叫 Voice Conversion
Discrete-Representation(离散表示

:把一个图像输入到autoencoder中,产生一vector,然后跟样本库中之前学习过产生的vector进行相似度对比,类似于transformer的query和key进行计算attention分数,再把这个最相似的拿去做decoder,最后输出原来的图像,越相似越好.
这样做的好处是:拿出来的vector是其中的某一维,那么肯定就是离散的,这样就实现了离散表示,从原来可能无穷个的表示维度,离散的表示出来.这个就是VQVAE,感觉是强行进行转换表达,聚类.

那么如果换成文字,就更简单了,输入到encoder后的那个向量肯定就是文字的精髓,那样肯定就直接拿到了
一些更多的应用:
VAE:variational auto-encoder,就是把autoencoder的decoder拿出来做一个生成网络,看输入一个vector能不能直接产生结果
可以做压缩:compression,当你的数据进入autoencoder的网络之后,就相当于给他一个压缩,然后decoder就是解压的过程,但是这个过程是有损的,会失真
语言模型(过去)
Introduce:语言模型可以对一段语言进行估计,信息检索,机器翻译,语音识别等任务有很重要的作用,简而言之就是一段长度为L的句子,预测其中 第1-L中的词,计算其概率,公式如下:
如果按照这个公式计算概率,如果长度变长,是非常难以计算的,所以研究者们又提出了一个简化模型—-n元模型(n-gram model),就是只计算n范围之内的概率,在n元模型中估算条件概率时,距离大于等于n的上文词会被忽略。但是当n越小他的语序信息就越得不到保留,如n=1时,完全看作单独的词,丢失了所有词序
为了更好地保留词序信息,构建更有效的语言模型,我们希望在n元模型中选用更大n。但是, n较大时,长度为n序列出现的次数就会非常少,在按照公式估计n元条件概率时,就会遇到数据稀疏问题,导致估算结果不准确。因此,一般在百万词级别的语料中,三元模型是比较常用的选择
同时也需要配合相应的平滑算法,进一步降低数据稀疏带来的影响
1.神经网络语言模型(nnlm):
2001年,Bengio 等人正式提出神经网络语言模型(Neural Network Language Model ,
NNLM。该模型在学习语言模型的同时,也得到了词向量
NNLM 同样也是对 n 元语言模型进行建模,估算 P(wi|wi−(n−1),...,wi−1)的值。但与传统方法不同的是,NNLM 不通过计数的方法对 n 元条件概率进行估计,而是直接通过一个神经网络结构,对其进行建模求解。

神经网络语言模型之所以能对 n 元条件概率进行更好的建模,缓解数据稀疏问题,是由于它使用词序列的词向量对上文进行表示;
而传统语言模型使用的是各词的独热表示作为上文的表示。词的独热表示(one-hot representation)是一个 |V| 维向量。对于词 vi,其独热表示向量中,只有第 i 维是 1,其余各维均是 0。在长度为 n − 1 的上文序列中,如果采用独热表示,则是一个 |V|n−1 维的0/1 向量,空间非常稀疏;而使用词向量表示时,则是一个 (n − 1)|e| 维的实数向量
利用这种低维的实数表示,可以使相似的上文预测出相似的目标词
而传统模型中只能通过相同的上下文预测出相同的目标词
e是词向量的维度,h是隐藏层的维度,v是输出层的维度
神经网络语言模型中的词向量出现在两个地方。在输入层中,各词的词向量存于一个 |e|×|V| 维的实数矩阵中。词 w 到其词向量 e(w) 的转化就是从该矩阵中取出一列。值得注意的是,隐藏层到输出层的权重矩阵 U 的维度为 |V| × |h|,
可以将其看做 |V| 个 |h| 维的行向量,其中的每一个向量,均可以看做某个词在模型中的另一个表示 e′。在不考虑 W 的情况下,每个词在模型中有两套词向量,其中 e(w) 为词 w 作为上下文时的表示,而 e′(w) 为词 w 作为目标词时的表示。
2。lbl(log双线性语言模型):
一、LBL 模型中,没有非线性的激活函数 tanh,而由于 NNLM 是非线性的神经网络结构,激活函数必不可少;二、LBL 模型中,只有一份词向量 e,也就是说,无论一个词是作为上下文,还是作为目标词,使用的是同一份词向量。其中第二点(只有一份词向量),只在原版的 LBL 模型中存在,后续的改进工作均不包含这一特点(基于lbl改进的模型))
对lbl的改进后的有两个比较重要的模型技术一个就是层级LBL和基于向量的逆语言模型IVLBL
部署本地语言模型
下载ollama→

然后在命令行ollama run model(Your model)
RAG —检索增强生成
让输出更加具体,更加全面准确,降低幻觉和时效性的问题,跟Finetuning区别就是,考试可以翻书提示你和学完整个学期后再着重复习再考试,先从向量数据库里去检索有用的信息,再增强query到prompt,最后一起生成出来

Cycle GAN(以encoder-decoder的角度

- 作者:LxAnC
- 链接:http://lxanc.top/technology/DL
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。